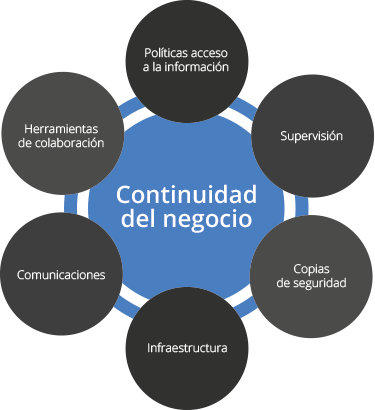
4. 1 Seguridad y respaldos Copia de Seguridad o Respaldo
Una "copia de seguridad", "copia de respaldo" o también llamado "backup" (su nombre en inglés) en tecnologías de la información e informática es una copia de los datos originales que se realiza con el fin de disponer de un medio para recuperarlos en caso de su pérdida.Las copias de seguridad son útiles ante distintos eventos y usos: recuperar los sistemas informáticos y los datos de una catástrofe informática, natural o ataque; restaurar una pequeña cantidad de archivos que pueden haberse eliminado accidentalmente, corrompido, infectado por un virus informático u otras causas; guardar información histórica de forma más económica que los discos duros y además permitiendo el traslado a ubicaciones distintas de la de los datos originales; etc.
El proceso de copia de seguridad se complementa con otro conocido como restauración de los datos (en inglés restore), que es la acción de leer y grabar en la ubicación original u otra alternativa los datos requeridos.
La pérdida de datos es muy común, el 66% de los usuarios de Internet han sufrido una seria pérdida de datos en algún momento.
Ya que los sistemas de respaldo contienen por lo menos una copia de todos los datos que vale la pena salvar, deben de tenerse en cuenta los requerimientos de almacenamiento. La organización del espacio de almacenamiento y la administración del proceso de efectuar la copia de seguridad son tareas complicadas.
Para brindar una estructura de almacenamiento es conveniente utilizar un modelo de almacenaje de datos. Actualmente (noviembre de 2010), existen muchos tipos diferentes de dispositivos para almacenar datos que son útiles para hacer copias de seguridad, cada uno con sus ventajas y desventajas a tener en cuenta para elegirlos, como duplicidad, seguridad en los datos y facilidad de traslado.
Antes de que los datos sean enviados a su lugar de almacenamiento se lo debe seleccionar, extraer y manipular. Se han desarrollado muchas técnicas diferentes para optimizar el procedimiento de efectuar los backups. Estos procedimientos incluyen entre otros optimizaciones para trabajar con archivos abiertos y fuentes de datos en uso y también incluyen procesos de compresión, cifrado, y procesos de duplicación, entendiéndose por esto último a una forma específica de compresión donde los datos superfluos son eliminados.
Muchas organizaciones e individuos tratan de asegurarse que el proceso de backup se efectúe de la manera esperada y trabajan en la evaluación y la validación de las técnicas utilizadas. También es importante reconocer las limitaciones y losfactores humanos que están involucrados en cualquier esquema de backup que se utilice. Las copias de seguridad garantizan dos objetivos: integridad y disponibilidad.
4.1.1 Espejeo
El Mirroring (Base de Datos Espejo) proporciona una solución de alta disponibilidad de bases de datos, aumenta la seguridad y la disponibilidad, mediante la duplicidad de la base de datos.Esta tecnología está disponible a partir de la versión de SQL Server 2005 (es la evolución del log shipping presente en versiones anteriores).
En el Mirroring tenemos un servidor principal/primario que mantiene la copia activa de la base de datos (bbdd accesible). Otro servidor de espejo que mantiene una copia de la base de datos principal y aplica todas las transacciones enviadas por el Servidor Principal (en el que no se podrá acceder a la bbdd). Y un servidor testigo/arbitro que permite recuperaciones automáticas ante fallos, monitoriza el servidor principal y el de espejo para en caso de caída cambiar los roles (servidor opcional, no es obligatorio).

Existen varios tipos de mirroring:
- Alta disponibilidad: Garantiza la consistencia transaccional entre el servidor principal y el servidor de espejo y ofrece Automatic Fail over mediante un servidor testigo.
- Alta Protección: Garantiza la consistencia transaccional entre el servidor principal y el espejo.
- Alto Rendimiento: Aplica las transacciones en el Servidor Espejo de manera asíncrona ocasionando mejoras significativas en el rendimiento del servidor principal pero no garantiza que dichas transacciones se hallan realizado de manera exitosa en el espejo.
Espejeo de Datos en un DBMS.
Base de Datos Espejo (Database Mirroring).
Donde actúan dos servidores o más para mantener copias de la base de datos y archivo de registro de transacciones.
El servidor primario como el servidor espejo mantienen una copia de la base de datos y el registro de transacciones, mientras que el tercer servidor, llamado el servidor árbitro, es usado cuando es necesario determinar cuál de los otros dos servidores puede tomar la propiedad de la base de datos. El árbitro no mantiene una copia de la base de datos. La configuración de los tres servidores de base de datos (el primario, el espejo y el árbitro) es llamado Sistema Espejo (Mirroring System), y el servidor primario y espejo juntos son llamados Servidores Operacionales (Operational Servers) o Compañeros (Partners).
Beneficios del espejeo de Datos en un DBMS
Esta característica tiene 3 modalidades que son Alto rendimiento, Alta Seguridad, y Alta Disponibilidad, este caso estamos hablando de las 2 primeras, las cuales el levantamiento es manual.
La creación de reflejo de la base de datos es una estrategia sencilla que ofrece las siguientes ventajas:
- Incrementa la disponibilidad de una base de datos.
- Si se produce un desastre en el modo de alta seguridad con conmutación automática por error, la conmutación por error pone en línea rápidamente la copia en espera de la base de datos, sin pérdida de datos. En los demás modos operativos, el administrador de bases de datos tiene la alternativa del servicio forzado (con una posible pérdida de datos) para la copia en espera de la base de datos. Para obtener más información, vea Conmutación de roles, más adelante en este tema.
- Aumenta la protección de los datos.
- La creación de reflejo de la base de datos proporciona una redundancia completa o casi completa de los datos, en función de si el modo de funcionamiento es el de alta seguridad o el de alto rendimiento. Para obtener más información, vea Modos de funcionamiento, más adelante en este tema.
Un asociado de creación de reflejo de la base de datos que se ejecute en SQL Server 2008 Enterprise o en versiones posteriores intentará resolver automáticamente cierto tipo de errores que impiden la lectura de una página de datos. El socio que no puede leer una página, solicita una copia nueva al otro socio. Si la solicitud se realiza correctamente, la copia sustituirá a la página que no se puede leer, de forma que se resuelve el error en la mayoría de los casos. Para obtener más información, vea Reparación de página automática (grupos de disponibilidad/creación de reflejo de base de datos).
Mejora la disponibilidad de la base de datos de producción durante las actualizaciones.
Para minimizar el tiempo de inactividad para una base de datos reflejada, puede actualizar secuencialmente las instancias de SQL Server que hospedan los asociados de creación de reflejo de la base de datos. Esto incurrirá en el tiempo de inactividad de solo una conmutación por error única. Esta forma de actualización se denomina actualización gradual. Para obtener más información, vea Instalar un Service Pack en un sistema con un tiempo de inactividad mínimo para bases de datos reflejadas.

Métodos de respaldo de un DBMS
Archivo de log
- Identificador de la transacción
- Hora de modificación
- Identificador del registro afectado
- Tipo de acción
- Valor anterior del registro
- Nuevo valor del registro
- Información adicional
Checkpoint
- Técnicas basadas en el registro histórico
- Paginación en la sombra o páginas en espejo
- Técnica de Recuperación Aries

4.1.2 Réplica
La replicación copia y mantiene los objetos de las bases de datos en las múltiples bases de datos que levantan un sistema distribuido. La replicación puede mejorar el funcionamiento y proteger la disponibilidad de las aplicaciones, porque alternan opciones de acceso de los datos existentes. Por ejemplo, una aplicación puede tener acceso normalmente a una base de datos local, más que a un servidor remoto para reducir al mínimo el tráfico de la red y alcanzar su funcionamiento máximo. Además, la aplicación puede continuar funcionando si el servidor local experimenta una falla, pero otros servidores con datos replicados siguen siendo accesibles.
La replicación se proporciona en los siguientes niveles:
- Replicación básica: las réplicas de tablas se gestionan para accesos de sólo lectura. Para modificaciones, se deberá acceder a los datos del sitio primario.
- Replicación avanzada (simétrica): amplían las capacidades básicas de sólo- lectura de la replicación, permitiendo que las aplicaciones hagan actualizaciones a las réplicas de las tablas, a través de un sistema replicado de la base de datos. Con la replicación avanzada, los datos pueden proveer lectura y acceso a actualizaciones a los datos de las tablas.
Modelo de replicación:
El modelo de Replicación que usa SQL es el de “Publicador – Suscriptor”. Este modelo consiste en Publicadores, Suscriptores y Distribuidores; las publicaciones y los artículos, y las suscripciones por tirón o empuje. Además, incorpora agentes de administración como Agente de Instantánea, Agente Lector de Registro, Agente de Distribución, y Agente de Mezcla. Todos los agentes pueden funcionar debajo del agente del servidor del SQL y se pueden administrar completamente por el Administrador del Servidor de SQL.

4.1.3 Métodos de respaldo
En mySQL existen varios métodos para la realización de un backup y esto se debe principalmente a que mySQL guarda las tablas como archivos y al tipo de tablas que se esté manejando (InnoDB, MyISAM, ISAM). Así por ejemplo para la presente práctica se utilizó el tipo de tabla InnoDB y el método de backup utilizado es el que funciona con este tipo de tablas.
InnoDB es una de las tecnologías de almacenamiento que utiliza mySQL, es de código abierto. Entre sus características principales están que soporta transacciones con características ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad), tiene bloque de registros e integridad referencial (cosa que no maneja ISAM, ni myISAM). Esta última es una de sus características más importantes pues una base de datos sin integridad referencial, es nada más un conjunto de datos que no denotan información.
Este tipo de almacenamiento también ofrece una alta fiabilidad y consistencia. El mismo gestiona el control de los datos y no se lo deja al sistema operativo, una de sus desventajas es que no tiene una buena compresión de datos, por lo que ocupa un poco más de espacio que myISAM
Elementos y frecuencia de respaldo
Normalmente cuando uno plantea que va a respaldar los datos de su PC a una persona en una compañía uno tiene que definir muy bien cuál es la información crítica para la empresa, por ejemplo, la música que guarde un empleado en su PC no es crítica para las actividades de la empresa ni lo son las fotos de su última fiesta. En cambio, su correo electrónico, proyectos, informes y papeles administrativos si lo suelen ser y tener un respaldo de estos es clave para el funcionamiento de la empresa en caso de cualquier eventualidad. Normalmente la data o información que es respaldada por las empresas es:
- Archivos creados por aplicaciones, como por ejemplo .doc, .odt, .xls, .mdb, pdf, .ppt entre otros.
- Archivos de correo electrónico
- Directorios telefónicos y de contactos
- Favoritos de los navegadores como Firefox e Internet Explorer
- Base de datos Configuraciones de los equipos
- Archivos de CAD, PSD, XCF, etc.
- Imágenes y Fotografías de proyectos
- Configuraciones de servicios
4.1.4 Métodos de recuperación
Cuando se trata de la recuperación de bases de datos distribuidas hay dos principales preocupaciones que deben de ser abordadas:
Integridad de datos. La base de datos distribuida debe ser restaurada o reparada de tal manera que no exista la corrupción. En términos generales, esto requiere que el proceso de recuperación de la base de datos distribuida sea consciente de las aplicaciones.
El software utilizado por la operación de recuperación tiene que conocer los requisitos específicos de la base de datos que está siendo recuperada. Por ejemplo, la mayoría de las aplicaciones de respaldo de clase empresarial soportan Exchange Server. Este soporte de Exchange Server significa que la aplicación respaldo sabe cómo manejar los puestos de control de la base de datos y los registros de transacciones de procesos como parte del proceso de recuperación.
Recuperación de punto en el tiempo. Por ejemplo, si está recuperando una base de datos de Active Directory en un controlador de dominio, es posible que desee desplegar el Active Directory de vueltaa un punto específico en el tiempo.
El problema es que Active Directory utiliza una base de datos distribuida y otros controladores de dominio están en línea. Cuando el proceso de recuperación de la base de datos distribuida se completa, el controlador de dominio recién restaurado alcanzará a otros controladores de dominio e iniciará un proceso de sincronización.
Esto trae al controlador de dominio recién restaurado a un estado actual que es consistente con los otros controladores de dominio. Si su objetivo era desplegar Active Directory de vuelta a un punto anterior en el tiempo, el proceso de sincronización deshará sus esfuerzos de recuperación. La solución para las bases de datos distribuidas es llevar a cabo una recuperación autoritaria, lo que esencialmente causa que el controlador de dominio recién restaurado sea tratado como la copia correcta de la base de datos de Active Directory.
En los entornos distribuidos de datos podemos encontrar lo siguientes:
Fallo de los nodos. Cuando un nodo falla, el sistema deberá continuar trabajando con los nodos que aún funcionan. Si el nodo a recuperar es una base de datos local, se deberán separar los datos entre los nodos restantes antes de volver a unir de nuevo el sistema.
Copias múltiples de fragmentos de datos. El subsistema encargado del control de concurrencia es el responsable de mantener la consistencia en todas las copias que se realicen y el subsistema que realiza la recuperación es el responsable de hacer copias consistentes de los datos de los nodos que han fallado y que después se recuperarán.
Transacción distribuida correcta. Se pueden producir fallos durante la ejecución de una transacción correcta si se plantea el caso de que al acceder a alguno de los nodos que intervienen en la transacción, dicho nodo falla.
Fallo de las conexiones de comunicaciones. El sistema debe ser capaz de tratar los posibles fallos que se produzcan en las comunicaciones entre nodos. El caso mas extremo es el que se produce cuando se divide la red. Esto puede producir la separación de dos o más particiones donde las particiones de cada nodo pueden comunicarse entre si pero no con particiones de otros nodos.
Para implementar las soluciones a estos problemas, supondremos que los datos se encuentran almacenados en un único nodo sin repetición. De ésta manera sólo existirá un único catálogo y un único DM (Data Manager) encargados del control y acceso a las distintas partes de los datos.
Para mantener la consistencia de los datos en el entorno distribuido contaremos con los siguientes elementos:
- Catálogo: Programa o conjunto de programas encargados de controlar la ejecución concurrente de las transacciones.
- CM (Cache Manager). Subsistema que se encarga de mover los datos entre las memorias volátiles y no volátiles, en respuesta a las peticiones de los niveles más altos del sistema de bases de datos. Sus operaciones son Fetch(x) y Flush(x).
- RM (Recovery Manager). Subsistema que asegura que la base de datos contenga los efectos de la ejecución de transacciones correctas y ninguno de incorrectas. Sus operaciones son Start, Commit, Abort, Read, Write, que utilizan a su vez los servicios del CM.
- DM (Data Manager). Unifica las llamadas a los servicios del CM y el RM.
- TM (Transaction Manager). Subsistema encargado de determinar que nodo deberá realizar cada operación a lo largo de una transacción.
Las operaciones de transacción que soporta una base de datos son: Start, Commit y Abort. Para comenzar una nueva transacción se utiliza la operación Start. Si aparece una operación commit, el sistema de gestión da por terminada la transacción con normalidad y sus efectos permanecen en la base de datos. Si, por el contrario, aparece una operación abort, el sistema de gestión asume que la transacción no termina de forma normal y todas las modificaciones realizadas en la base de datos por la transacción deben de ser deshechas.
4.2 Migración
La migración de bases de datos es generalmente una tarea compleja que no sólo supone transferir datos entre tipos de almacenaje y formatos de un servidor de base de datos a otro; sino que también supone reescribir sentencias SQL o incluso procedimientos (SPL) de lógica de negocio.
En comparación con los esquemas estándares de migración a mano, ofrecemos una potente gama de herramientas desarrolladas de probada eficacia en complejos módulos de bases de datos relacionales. Estas herramientas y nuestros especialistas pueden asegurar que las transiciones de las bases de datos se realicen perfectamente, independientemente de la naturaleza del sistema.
Desde la experiencia, estamos familiarizados con la complejidad, el coste que supone una larga migración de bases de datos y los problemas que aparecen durante el proceso cuando se emplean métodos inapropiados; ya que siempre comprobamos con los clientes potenciales que el uso de nuestras herramientas y métodos pueda ofrecer una ventaja significativa.
HERRAMIENTAS DE MIGRACIÓN
En comparación con la consultoría estándar de migraciones, la cual puede ofrecer poco más que soporte a la base de datos, nosotros tenemos gran experiencia en escribir grandes aplicaciones para empresas en sintaxis de la base de datos nativa y cross. Además, enseñamos a los equipos de las empresas una metodología y les proporcionamos una potente gama de herramientas para reducir costes y optimizar el proceso de migración.
4.3 Monitoreo
El término Monitoreo es un término no incluido en el diccionario de la Real Academia Española (RAE). Su origen se encuentra en monitor, que es un aparato que toma imágenes de instalaciones filmadoras o sensores y que permite visualizar algo en una pantalla. El monitor, por lo tanto, ayuda a controlar o supervisar una situación.
Esto nos permite inferir que monitoreo es la acción y efecto de monitorear, el verbo que se utiliza para nombrar a la supervisión o el control a través de un monitor. Por extensión, el monitoreo es cualquier acción de este tipo, más allá de la utilización de un monitor.
Monitoreo general de un DBMS
DAP— un término que Gartner desarrolló para remplazar el anterior concepto de DAM —se refiere a las suites de herramientas que se utilizan para apoyar la identificación y reportar comportamiento inapropiado, ilegal o de otra forma indeseable en las RDBMSs, con mínimo impacto en las operaciones y la productividad del usuario.
Estas suites han evolucionado de herramientas DAM — que ofrecían análisis de la actividad del usuario en las RDBMSs y alrededor de ellas— para abarcar un conjunto más integral de capacidades, que incluyen:
- Descubrimiento y clasificación.
- Gestión de vulnerabilidades.
- Análisis al nivel de aplicación.
- Prevención de intrusión.
- Soporte de seguridad de datos no estructurados.
- Integración de gestión de identidad y acceso.
- Soporte de gestión de riesgos.

Monitoreo general de un DBMS
La elección de un buen manejador de base de datos es de vital importancia ya que puede llegar a ser una inversión tanto en hardware como en software muy cuantioso, pero no solo eso, además va a determinar el centro de información de la empresa.
Los sistemas orientados a los datos se caracterizan porque los datos no son de una aplicación sino de una Organización entera que los va a utilizar; se integran las aplicaciones, se diferencian las estructuras lógicas y físicas. El concepto de relación cobra importancia. Originalmente las aplicaciones cubrían necesidades muy específicas de procesamiento, se centraban en una tarea específica.
Monitoreo de espacio en disco
Uno de los principales indicadores que se tiene que tomar en cuenta como DBA es el espacio disponible en disco. No es problema cuando se tiene un server o 2 para monitorear, sin embargo, cuando hay una cantidad considerable automatizar un proceso que lo haga es lo mejor. Dentro de SQL Server (7,2000,2005) hay un procedimiento no documentado que nos puede ayudar a cumplir este cometido.
El procedimiento es XP_FIXEDDRIVES, no lleva parámetros ni nada y nos regresan todos los discos a los que tiene acceso SQL Server y su espacio disponible en Megabytes. Si esta en clúster mostrara todos los discos, aunque los discos no estén en el mismo grupo que la instancia, lo que puede llegar a confundir.
Dejo a consideración de cada quien como utilizarlo, ya sea mandando un mail con el resultado u opciones más complejas como el revisar un porcentaje y en base a eso tomar una acción.
Monitoreo de logs
Las revisiones deben realizarse sobre el archivo de alerta de ORACLE (alert.log) y sobre los archivos de rastreo de procesos de background y de usuarios para identificar errores que se presenten a nivel de base de datos o de sistema operativo.
Los archivos de alerta útiles para el diagnóstico de información que contiene ORACLE y que se utilizan para la detección de errores en la base de datos son:
Archivo de Logs de alerta (alert.log)
El Alert Log registra errores en forma cronológica, provenientes de la operación diaria de la Base de Datos. La ubicación actual del archivo es la ubicación por defecto establecida por ORACLE y se verifica mediante el parámetro BACKGROUND_DUMP_DEST del archivo init.ora:
BACKGROUND_DUMP_DEST = E:\U01\ORACLE\UCBL\ADMIN\bdump
La revisión de este archivo en forma periódica permite detectar errores internos (ORA-600) y errores de corrupción de bloques (ORA-1578). Adicionalmente, permite monitorear las operaciones de la base de datos (CREATE DATABASE, STARTUP, SHITDOWN, ARCHIVE LOG y RECOVER) y ver los parámetros que no se muestran por defecto en la inicialización. Fuente: http://proyecto359.webnode.mx/unidad5/
4.4 Auditoría
Auditoria: Es el proceso que permite medir, asegurar, demostrar, monitorear y registrar los accesos a la información almacenada en las bases de datos incluyendo la capacidad de determinar:
- Quién accede a los datos
- Cuándo se accedió a los datos
- Desde qué tipo de dispositivo/aplicación
- Desde que ubicación en la Red
- Cuál fue la sentencia SQL ejecutada
- Cuál fue el efecto del acceso a la base de datos
objetivo de:
- Mitigar los riesgos asociados con el manejo inadecuado de los datos.
- Apoyar el cumplimiento regulatorio.
- Satisfacer los requerimientos de los auditores.
- Evitar acciones criminales.
- Evitar multas por incumplimiento.
No hay comentarios:
Publicar un comentario